

1. Redis 데이터의 영속성
Redis는 In-memory DB 임에도 불구하고, 메모리 데이터를 디스크에 저장할 수 있는 특징이 있다.
그래서 redis가 꺼졌다가 재시작 되더라도, 디스크에 저장해놓은 데이터를 다시 읽어 메모리에 로딩하기 때문에 데이터가 유실되지 않는다.
이런 영속성 기능은 휘발성 메모리 DB를 데이터 스토어로서 활용한다는 장점이 있지만 이 기능 때문에 장애의 주 원인이 되기도 한다.
Redis에서 데이터를 저장하는 방법은 크게 RDB (snapshotting) 방식과 AOF (Append only file) 두가지가 있다.
RDB 방식
- 특정한 각격마다 메모리에 있는 레디스 데이터 전체를 디스크에 쓰는 것
AOF 방식
- 명령이 실행될때 마다 데이터를 파일에 기록하여 데이터의 손실이 거의 없음
두 가지 방식이 어떻게 다른지 자세하게 알아보고 활용법을 살펴보자.
2. RDB
Redis는 인메모리 데이터를 주기적으로 파일에 저장하는데, Redis 프로세스가 장애로 인해 종료되더라도 해당 파일을 읽어들이면 이전의 상태를 동일하게 복구할 수 있다.
RDB(snapthot)는 순간적으로 메모리에 있는 내용을 스냅샷을 떠서 DISK에 옮겨 담는 방식이다. 스냅샷을 뜬다는 말은 특정 시점의 메모리에 있는 데이터를 바이너리 파일로 저장하는 뜻이다.
따로 설정하지 않았다면 Redis는 기본적으로 RDB 방식으로 백업을 진행한다.
Redis가 설치되어 있는 폴더로 가보면 .rdb 라는 확장자 파일에 인메모리 데이터를 저장하고 있는 모습을 확인할 수 있다.

RDB 방식은 메모리의 snapshot을 그대로 저장하고 비교적 작은 사이즈의 파일로 백업하기 때문에 서버를 재구동시할 때 snapshot을 다시 읽으면 되므로 로딩 속도가 빠른 장점이 있다.
그러나, snapshot을 추출하는데 시간이 오래걸리고 도중에 서버가 꺼지면 이후의 데이터를 모두 사라진다는 단점이 있다. 실제로 SAVE 옵션으로 50GB 의 메모리 상태를 저장한다면 7 ~ 8분 정도 소요된다고 한다.
RDB 기본 설정은 아래와 같다.

- 3600초 안에 1개 이상의 데이터가 변경되면 저장
- 300초 안에 100개 이상의 데이터가 변경되면 저장
- 60초안에 10000개 이상의 데이터가 변경되면 저장
3.1 AOF (Append Only File)
AOF(Append On File) 방식은 redis의 모든 write/update 연산 자체를 모두 log 파일에 기록하는 형태이다.
AOF는 쓰기 명령에 대해 추가하며 기록되기 때문에 파일 사이즈가 크다. 사이즈가 크기 때문에 서버 시작시 로딩속도가 느리다.
default로 appendonly.aof 파일에 기록되며, 조회를 제외한 입력/수정/삭제 명령이 실행될 때 마다 기록된다.
그리고 서버가 재시작될 때, log에 기록된 write/update 연산을 재 실행하는 형태로 데이터를 복구하는 방식이다.
즉, 다음과 같은 순서로 데이터가 저장된다.
- 클라이언트가 Redis 에 업데이트 관련 명령을 요청한다.
- Redis 는 해당 명령을 AOF에 저장한다.
- 파일쓰기가 완료되면 실제로 해당 명령을 수행해서 Redis 메모리에 내용을 변경한다.
이처럼, operation이 발생할때 마다 매번 기록하기 때문, RDB 방식과는 달리 특정 시점이 아니라 항상 현재 시점까지의 로그를 기록할 수 있으며, 기본적으로 non-blocking 으로 동작 된다.
AOF는 log 파일에 대해서만 append하기 때문에 log write 속도가 빠르고 어떤 시점에 서버가 다운되더라도 데이터가 사라지지 않는 장점이 있다. RDB는 바이너리 파일이라서 수정이 불가능했지만, AOF 로그 파일은 text 파일이므로 편집이 가능하다.
AOF 활용 예시
만일 실수로 flushall 명령으로 메모리에 있는 데이터를 모두 날렸을 때, 레디스 서버를 shutdown하고 appendonly.aof 파일에서 flushall 명령을 제거 한 후 레디스를 다시 시작하면 데이터 손실없이 데이터를 살릴 수 있다.
AOF 항목
- appendolny
- AOF 파일 사용 여뷰
- yes / no
- appendfilename
- AOF 파일 이름 설정
- appendfsync
- 운영체제의 fsync()에 의한 지연된 쓰기 옵션 (메모리 => 디스크)
- no: fsync() 사용 없이 즉시 쓰기, 가장 빠름
- always: 항상 fsync() 사용
- 느리지만 안전함
- 데이터 유실의 염려는 없으나, 성능이 매우 떨어짐
3.2 AOF redis.conf 설정 방식
레디스는 서버가 시작될 때 데이터 파일을 읽는다.
이때 어떤 데이터 파일을 읽을지는 redis.conf 설정 파일의 appendonlyfile 설정을 따르게 된다.
AOF 활성화
처음 redis를 설치하고 conf파일을 보면 아래 사진과 같이 되어있다. no 를 yes로 바꿔주어 aof 를 활성화 시켜주자.
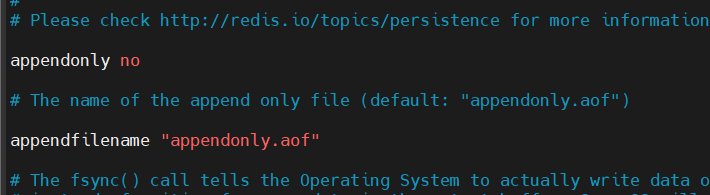
appendonly yes- appendonlyfile yes : aof 파일을 읽음
- appendonlyfile no : rdb 파일을 읽음
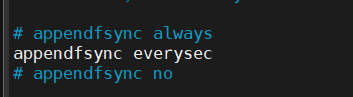
aof에 기록되는 시점을 지정
appendfsync는 appendonly 파일에 데이터가 쓰여지는 시점을 정하는 파라미터이다. AOF 는 파일에 저장할 때 파일을 버퍼 캐시에 저장하고 적절한 시점에 이 데이터를 디스크로 저장하는데 appendfsync 는 디스크와 동기화를 얼마나 자주 할 것인지에 대해 설정하는 값으로 다음과 같이 3가지 옵션이 존재한다.
always : 명령 실행 시 마다 AOF에 기록. 데이터 유실은 거의 없지만 성능이 매우 떨어짐.
everysec : 1초마다 AOF에 기록. 권장
no : AOF에 기록하는 시점을 OS가 정함(일반적으로 리눅스의 디스크 기록 간격은 30초). 데이터가 유실될 수 있음
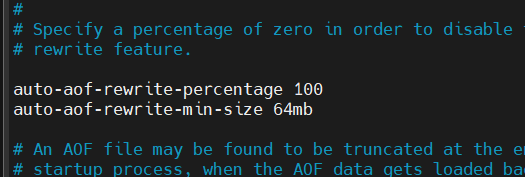
AOF Rewrite 설정
rewrite란 AOF 파일의 상태가 특정 조건(파일 사이즈가 얼마 이상) 일 때 AOF 파일을 현재 상태에 맞춰서 설정에 따라 덮어쓰기 하거나 새로 생성된다.
처음 레디스 서버가 시작할 시점의 AOF 파일 사이즈가 100% 이상 커지면 rewrite 하게 되어있다.
만약 레디스 서버 시작 시 AOF 파일 사이즈가 0이었다면, auto-aof-rewrite-min-size를 기준으로 rewrite 한다.
하지만 min-size가 64mb 이하이면 rewrite를 하지 않는다. 파일이 작을 때 rewrite가 자주 발생하는 것을 방지하기 위해서이다.
예를 들어 레디스 서버가 처음 시작할 때 1mb 사이즈였다고 가정하면 2mb가 됐을 때 rewrite를 수행할 것이다. 이를 막기 위해 min-size 옵션이 있는 것이다.
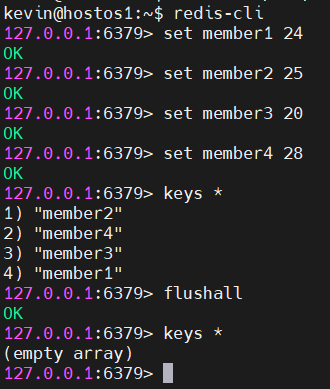
3.3 AOF를 활용하여 유실된 데이터 복구하기
redis에 여러 값이 있다가 db가 전부 날라갔을 때 이를 복구하는 과정을 알아보자.
우선 dummy data를 넣고, flushall 명령어를 사용해 데이터를 전부 날려주었다.
ubuntu 기준으로 appendonly.aof 파일은 /var/lib/redis/appendonly.aof 위치에 저장된다.
- AOF는 명령 실행 순서대로 텍스트로 쓰여즈며 편집이 가능하다.
- * 는 명령 시작을 나타낸다. 숫자는 명령과 인수의 개수이다.
- $ 는 명령이나 인수, 데이터의 바이트 수이다. (한글은 UTF8로 했을 경우 한 글자에 3바이트)
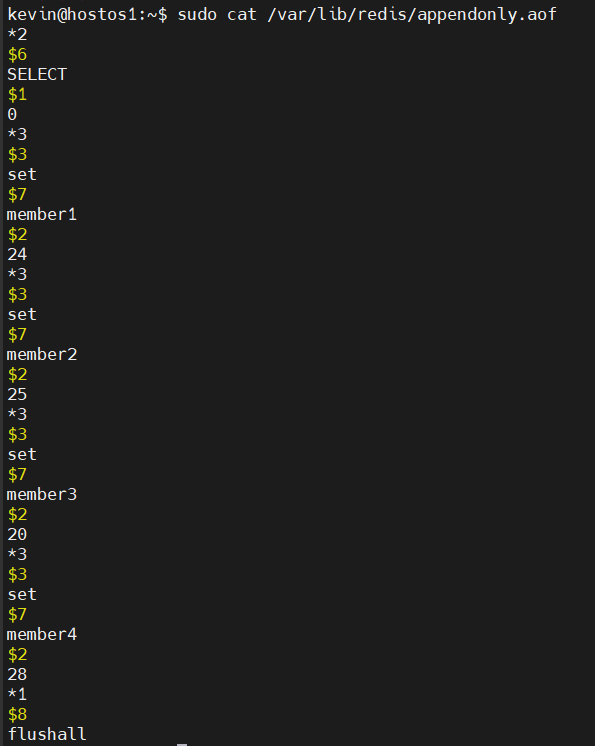
이제 편집기로 flushall을 지워주고 저장해주자.
그리고 redis를 재시작 해주면 데이터가 복구되어있는걸 확인할 수 있다.
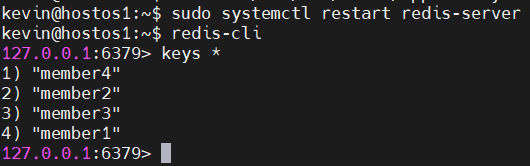
4. RDB VS AOF 선택 기준
RDB 사용 주의할 점
RDB(Snapshot) 방식의 문제점은 매우 명확한데, Redis에 장애가 발생했을 때 백업 시점을 제외한 중간 시점에서 발생한 데이터는 유실될 수 있다는 것이다.
RDB 방식에서 데이터를 백업할 때 사용하는 save, bgsave 두가지가 있다.
save는 싱글 스레드로 수행하기 때문에 작업이 완료되기 까지 모든 요청이 대기하게 된다.
따라서 bgsave 명령어로 background 자식 프로세스를 통해 백업 작업을 수행하도록 권장하는 편이고, default 값은 bgsave이다.
하지만 bgsave 명령어를 수행할 땐 메모리 사용률을 신경써야 한다.
redis 서비스에서 사용중인 데이터는 모두 메모리 위에 있는데 이를 “서비스 영향 없이” 스냅샷으로 저장하기 위해서는 Copy-on-Write(COW) 방식을 사용한다.
자식 프로세스 fork() 후 부모 프로세스의 메모리에서 실제로 변경이 발생한 부분만 복사하게 되는데, 만일 write 작업이 많아서 부모 페이지 전부에 변경이 발생하게 되면 부모 페이지 전부를 복사하게 되는 현상이 발생하게 된다.
AOF 사용 주의할 점
언뜻 보면 "쓰기 작업의 기록을 저장해 replay하는 형식으로 복구 할수 있기 때문에 안정적이고에 이상적이지 않느냐" 라고 생각할 수 있으나, 단순히 그렇지만은 않다.
예를 들어 0이라는 정수형의 데이터가 있다고 가정하자.
100번의 Increment 작업을 통해 100으로 만들었다면 AOF에선 100개의 명령 기록을 저장하고 있을 것이다.
RDB 방식이었다면 단순히 100이란 하나의 데이터를 복구하면 되는 작업이지만 AOF일 경우 100번의 명령 작업을 통해 데이터를 복구해야한다.
이런 작업에선 AOF는 취약하다.
그럼 어떤 방식을 채택해야할까??
백업이 필요는 하지만 어느 정도의 데이터 손실을 감수할 수 있는 경우 RDB를 단독으로 사용하는것이 좋고
장애 상황 직전까지 모든 데이터가 보장되어야 할 경우 AOF를 사용하는 것이 좋다.
하지만 RDB와 AOF 방식의 장단점을 상쇄하기 위해 두 가지 방식을 혼용해서 사용하는 것을 권장하고 있다.
주기적으로 RDB로 백업하고, 다음 snapshot까지의 저장을 AOF방식으로 수행하는 식으로 혼용한다.
이렇게 함으로써 서버가 재시작될 때 백업된 RDB 데이터를 복구하고, 비교적 적은 양의 AOF 로그만 읽어드리면 되기 때문에 시간을 절약하고 데이터의 유실을 완전히 방지할 수 있다.
당연하겠지만 각자의 상황에 맞게 백업 방식을 설정해 도입하는 것이 좋기 때문에 정답은 없다.
'DB 🔑' 카테고리의 다른 글
| [replication] mysql Replication 으로 DB 부하 분산 시키기 (0) | 2024.04.11 |
|---|---|
| [Neo4j] Graph Database란? RDBMS와 비교, neo4j 도입 이유 (2) | 2024.03.27 |
| [Lock] DB Lock & JPA Lock 코드로 살펴보자 (MySQL) (0) | 2024.02.20 |
| [Index] MySQL 성능 최적화 (+실행 계획) (0) | 2024.02.19 |
| [Index] 데이터베이스 인덱스 파헤치기 (1) | 2024.02.18 |