

Mysql의 Replicatoin 개념을 정리하고 프로젝트 중 AI 모델 재학습 시 900만 건의 데이터를 조회하면서 생기는 DB의 부하를 줄이기 위한 포스터입니다.
1. 복제(Replication)
복제(Replication)는 1개 이상의 레플리카(replica) 저장소가 소스 저장소와 동기화를 자동으로 유지하는 과정이다. 사용하기 위한 최소 구성은 Master / Slave이다.
Master DBMS 역할
웹서버로 부터 데이터 등록/수정/삭제 요청시 바이너리로그(Binarylog)를 생성하여 Slave 서버로 전달하게 된다. (웹서버로 부터 요청한 데이터 등록/수정/삭제 기능을 하는 DBMS로 많이 사용)
Slave DBMS 역할
Master DBMS로 부터 전달받은 바이너리로그(Binarylog)를 데이터로 반영하게 된다. (웹서버로 부터 요청을 통해 데이터를 불러오는 DBMS로 많이 사용)
2. Mysql Repication 사용 목적
mysql 리플리케이션의 사용목적은 크게 실시간 Data 백업과 여러대의 DB 서버의 부하를 분산시킬 수 있다.
먼저 데이터의 백업이다.
예를 들어 Master 서버를 데이터의 원본서버, Slave 서버를 백업 서버로 지칭하였다.
Master 서버에 DBMS의 등록/수정/업데이트가 생기는 즉시 Slave 서버의 변경된 데이터를 전달하게 된다. 이러한 과정으로 백업을 할 수 있으며, Master 서버의 장애가 생겼을 경우 Slave 서버를 DB로 사용할 수 있다.

DBMS의 부하 분산이다.
사용자의 폭주로 인해 1대의 DB서버로 감당할 수 없을 때, MySQL 레플리케이션을 이용하여 같은 DB 데이터를 여러대로 만들 수 있기 때문에 부하를 분산시켜줄 수 있다.
위에서도 얘기했듯이 Master 서버는 등록/수정/삭제를 처리하는 서버로 사용하고, Slave 서버는 서버의 데이터를 읽는 용도로 사용하며 부하를 분산시킬 수 있다.
이 외에도 복제의 장점들엔 다음과 같은 것들이 있다.
- 분석
- 원본 데이터에 실시간 데이터가 생성되고, 원본 데이터에 성능 이슈없이 레플리카에서 분석을 할 수 있다.
- 원거리 데이터 분산
- 원본데이터에 접근하지 않고도, 원격 사이트에서 사용 할 로컬 데이터 복사본을 생성할 수 있습니다.
3. 복제의 원리
아래는 MySQL의 Master-Slave 복제 원리이다.
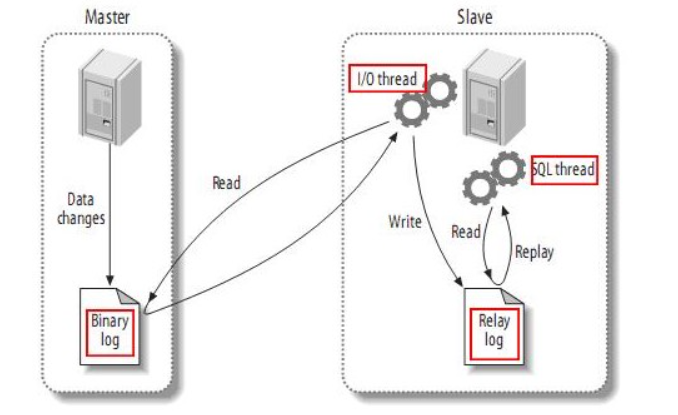
MySQL에서 복제는 바이너리 로그 파일에 데이터에 대한 모든 변경사항을 기록한다.
1. 레플리카가 초기화가 된다면, 2개의 쓰레드 작업을 생성
2. 하나는 I/O 쓰레드로 원본 인스턴스에 연결하고 한 줄씩 바이너리 로그를 읽는다. 그리고 레플리카 서버의 Relay 로그에 해당 내용들을 복사.
3. 두번째 쓰레드는 SQL 쓰레드로, relay 로그를 읽고 레플리카 인스턴스에 최대한 빠르게 적용다.
4. Replication 전 주의 사항
mysql replication을 진행하기 전 다음과 같이 주의해야 하는 몇 가지 사항들이 있다.
1. 호환성을 위해 Replication을 사용하는 MySQL의 버전은 동일하게 맞추기
2. Replication을 사용하기에 MySQL 버전이 다른 경우 Slave 서버가 상위 버전이어야 한다.
3. Replication을 가동시에 Master 서버, Slave 서버 순으로 가동시켜야 한다.
5. 구성해보기
두 개의 우분투 환경에서 해보려다 간단하게 Docker를 사용해서 구성해보기로 했다.
5-1. master DB 생성
master 컨테이너 실행 후 컨테이너 내부 접속, 설정 파일 수정을 위해 vim 설치
vim 설치가 안 될 경우, 로컬에서 my.cnf를 생성해 docker cp로 넣어주자. 이미지 마다 apt를 지원해주는 이미지도 있고 아닌 것도 있다.
$ docker run -p 3306 --name mysql-master -e MYSQL_ROOT_PASSWORD=1234 -d mysql:8-debian
$ docker exec -it mysql-master /bin/bash
$ apt-get update
$ apt-get install -y vim
vi 명령어로 /etc/mysql/my.cnf 파일을 열고, 아래와 같이 2줄을 추가
log-bin=mysql-bin
server-id=1
기존 운영중인 DB를 Replication할 경우 데이터를 백업해야 하는데 이때 보통 dump를 많이 사용한다. dump시 성능 향상을 올려주려면 buffer size를 늘려 진행하면 된다.
아래는 dummy data를 넣었지만 추후에 대용량 데이터 셋을 insert해야했기 때문에 아래 옵션도 추가해주었다.
innodb_buffer_pool_size = 4G
innodb_log_file_size = 1G
현재 사용중인 버퍼 사이즈를 확인하려면 아래 명령어를 mysql에 입력해주면 된다.
SHOW VARIABLES LIKE 'innodb_buffer_pool_size';
log bin
업데이트되는 모든 쿼리들이 Binary log 파일에 기록된다. 기본적으로 Binary log 파일은 MySQL의 data directory인 /var/lib/mysql/ 에 호스트명-bin.000001, 호스트명-bin.000002 형태로 생성된다.
이때, log-bin 설정을 변경하면 Binary log 파일의 경로와 파일명의 접두어를 변경할 수 있다.
위에선 log-bin=mysql이라 설정했기 때문에 mysql-bin.000001, mysql-bin.000002 이름으로로 Binary log 파일이 생성된다.
server-id
설정에서 서버를 식별하기 위한 고유 ID값이다. master, slave 각각 다르게 설정해야 한다.
도커를 재시작하여 설정 변경 적용 후 도커 내부에 다시 접속하여 설정이 제대로 적용되었는지 확인
$ docker restart mysql-master
$ docker exec -it mysql-master /bin/bash
$ mysql -u root -p
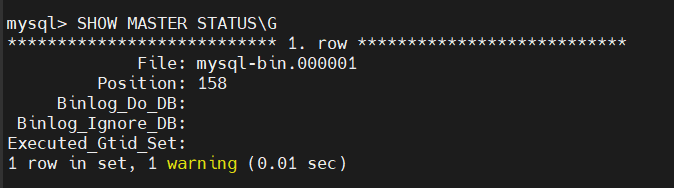
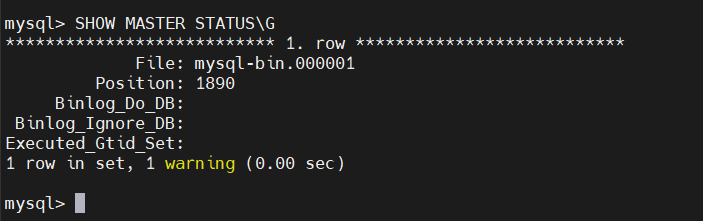
mysql> SHOW MASTER STATUS\G
현재 바이너리 로그 파일명이고, Position은 현재 로그의 위치를 나타낸다.
master DB에 계정 생성
master DB에서 사용할 계정을 생성한다. 이 계정이 slave DB에서 복제할 예정이다. dgjinsu 라는 계정을 새로 생성하고, 모든 ip에 대해서 권한을 열어준다.
$ CREATE USER 'dgjinsu'@'%' IDENTIFIED BY '1234';
//sha256_password
$ ALTER USER 'dgjinsu'@'%' IDENTIFIED WITH mysql_native_password BY '1234';
$ GRANT REPLICATION SLAVE ON *.* TO 'dgjinsu'@'%';
$ FLUSH PRIVILEGES;
MySQL 5.8부터는 Password Auth방식이 caching_sha2_password 방식으로 변경되었다고 한다. 따라서 위와 같이 유저를 생성할 때 IDENTIFIED WITH mysql_native_password BY 로 생성해야한다. 그렇지 않으면 아래의 에러를 만날 수 있다.
error connecting to master 'replication
user@mysql-primary:3306' - retry-time: 60 retries: 1 message: Authentication plugin 'caching
sha2_password' reported error: Authentication requires secure connection.
전부 입력했다면 방금 생성된 계정이 보일 것이다.
$ SELECT User, Host FROM mysql.user;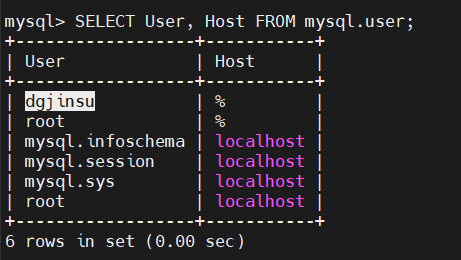
database, table을 만들고 아무 데이터나 삽입해준다.
master 컨테이너로 돌아와서, dump를 해준다.
생성한 dump.sql 파일을 로컬 환경으로 가져와준다.
$ mysqldump -u root -p bookclub > dump.sql // 컨테이너에서 실행
$ docker cp mysql-master:dump.sql . // 로컬에서 실행
5.2 slave DB 생성
slave DB를 생성하기 위해 새로운 컨테이너 mysql-slave 생성
docker run -p 3306 --name mysql-slave -e MYSQL_ROOT_PASSWORD=1234 --link mysql-master -d docker.io/mysql
slave 컨테이너도 my.cnf 파일을 편집해주자
위에서 했던 것처럼 vi 설치해준 후 아래와 같이 id를 설정해주자.
[mysqld]
server-id=2
설정했다면 적용을 위해 docker 컨테이너를 restart
로컬 환경에 옮겨뒀던 dump 파일을 slave 컨테이너로 복사하고, dump 파일을 적용해준다.
$ docker cp dump.sql mysql-slave:.
$ docker exec -it mysql-slave /bin/bash
$ mysql -u root -p
mysql> CREATE DATABASE test;
mysql> exit
$ mysql -u root -p test < dump.sql
5.3 slave를 master와 연결
master mysql에 접속해 SHOW MASTER STATUS\G 를 이용해 Position을 확인해준다.
혹은 SHOW BINARY LOG STATUS 을 사용하여 확인
처음 확인했을 때 보다 증가한걸 확인할 수 있다.
mysql-slave 컨테이너로 돌아와 mysql-master를 변경하고 slave를 시작한다.
mysql> CHANGE MASTER TO MASTER_HOST='mysql-master', MASTER_USER='dgjinsu', MASTER_PASSWORD='1234', MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=1890;
Query OK, 0 rows affected, 8 warnings (0.04 sec)
mysql> START SLAVE;
Query OK, 0 rows affected, 1 warning (0.02 sec)
MASTER_HOST : master 서버의 호스트명
MASTER_USER : master 서버의 mysql에서 REPLICATION SLAVE 권한을 가진 User 계정의 이름
MASTER_PASSWORD : master 서버의 mysql에서 REPLICATION SLAVE 권한을 가진 User 계정의 비밀번호 MASTER_LOG_FILE : master 서버의 바이너리 로그 파일명
MASTER_LOG_POS : master 서버의 현재 로그의 위치
slave에서 연결정보를 조회해 보면, 아래와 같이 mysql-master와 연결된 정보가 나온다.
위에서 얘기했던 두 가지 스레드인 Slave_IO 와 Slave_SQL 이 적상적으로 Running 되고 있는 것을 확인할 수 있다.
mysql> SHOW SLAVE STATUS\G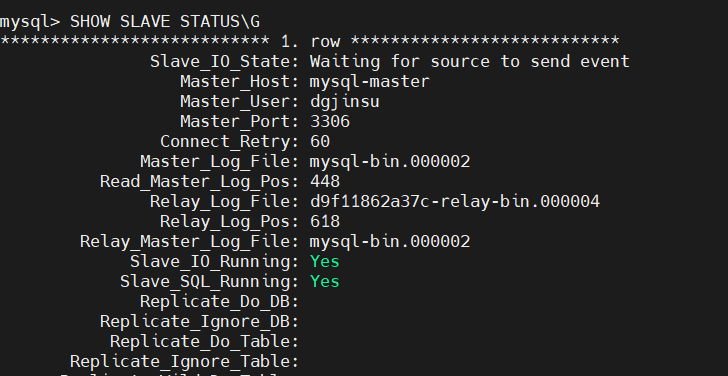
이제 Master 컨테이너로 들어가 테이블에 데이터를 하나 추가하면 slave에서도 잘 뜨는 것을 볼 수 있다.

6. SpringBoot에서 DataSource 분기
데이터베이스 서버를 Source - Replica 로 이중화 하였으므로, 스프링부트에서 사용하는 DataSource도 Master-Slave 에 맞게 2개를 써야한다. readOnly = true 트랜잭션은 Slave DataSource를, readOnly = false 인 트랜잭션은 Master DataSource를 사용하도록 분기해야한다.
application.yml
spring:
datasource:
master:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: [url]
username: [username]
password: [password]
slave:
driver-class-name: com.mysql.cj.jdbc.Driver
jdbc-url: [url]
username: [username]
password: [password]
DataBaseConfig.class
@Configuration
@EnableAutoConfiguration(exclude = {DataSourceAutoConfiguration.class}) // 스프링 부트의 자동 데이터베이스 구성을 비활성화
@EnableTransactionManagement // 트랜잭션 관리를 활성화
@EnableJpaRepositories(basePackages = {"test"}) // JPA 리포지토리를 활성화하고, 패키지 스캔 경로를 지정
public class DataBaseConfig {
// 마스터 데이터베이스 설정을 위한 빈
@Bean
@ConfigurationProperties(prefix = "spring.datasource.master")
public DataSource masterDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
// 슬레이브 데이터베이스 설정을 위한 빈
@Bean
@ConfigurationProperties(prefix = "spring.datasource.slave")
public DataSource slaveDataSource() {
return DataSourceBuilder.create().type(HikariDataSource.class).build();
}
// 라우팅
@Bean
public DataSource routingDataSource(@Qualifier("masterDataSource") DataSource master,
@Qualifier("slaveDataSource") DataSource slave) {
ReplicationRoutingDataSource routingDataSource = new ReplicationRoutingDataSource();
HashMap<Object, Object> sources = new HashMap<>();
sources.put(DATASOURCE_KEY_MASTER, master);
sources.put(DATASOURCE_KEY_SLAVE, slave);
routingDataSource.setTargetDataSources(sources);
routingDataSource.setDefaultTargetDataSource(master);
return routingDataSource;
}
// 데이터베이스에 접근하는 기본적인 데이터 소스를 설정
@Primary
@Bean
public DataSource dataSource(@Qualifier("routingDataSource") DataSource routingDataSource) {
return new LazyConnectionDataSourceProxy(routingDataSource);
}
}
ReplicationRoutingDataSource.class
Spring Boot에서 MySQL Replica를 이용해 트랜잭션에서 읽기 전용은 slave DB에서 처리하고,
쓰기는 master DB에서 처리하도록 설정해 보자.
이를 위해서 master, slave DB 중 어느 DB를 선택하는지 설정하는 AbstractRoutingDataSource와 읽기 전용 트랜잭션에 slave DB 가 커넥션 되도록 하는 LazyConnectionDataSourceProxy을 사용한다.
AbstractRoutingDataSource는 spring-jdbc 모듈에 포함되어 있는 클래스로, 여러 데이터소스를 등록하고 특정 상황에 원하는 데이터소스를 사용할 수 있도록 추상화한 클래스이다.
determineCurrentLookupKey() 메서드를 재정의하여, 읽기 전용일 경우 slave를, 아닌 경우 master를 반환하도록 해줬다.
@Slf4j
public class ReplicationRoutingDataSource extends AbstractRoutingDataSource {
public static final String DATASOURCE_KEY_MASTER = "master";
public static final String DATASOURCE_KEY_SLAVE = "slave";
@Override
protected Object determineCurrentLookupKey() {
// 현재 트랜잭션이 읽기 전용인지 확인
boolean isReadOnly = TransactionSynchronizationManager.isCurrentTransactionReadOnly();
String dataSourceKey = (isReadOnly) ? DATASOURCE_KEY_SLAVE : DATASOURCE_KEY_MASTER;
log.info("Selected DataSource: {}", dataSourceKey);
return dataSourceKey;
}
}
이렇게 트랜잭션에 따라 각자 다른 DB가 선택되는걸 확인할 수 있다.


'DB 🔑' 카테고리의 다른 글
| [DB] 자연키와 인조키 중 어떤걸 기본키로 둬야 할까? (1) | 2024.12.16 |
|---|---|
| [Neo4j] Graph Database란? RDBMS와 비교, neo4j 도입 이유 (1) | 2024.03.27 |
| [Redis] redis에서 데이터 영구 저장하는 방법 (RDB / AOF) (0) | 2024.03.09 |
| [Lock] DB Lock & JPA Lock 코드로 살펴보자 (MySQL) (0) | 2024.02.20 |
| [Index] MySQL 성능 최적화 (+실행 계획) (0) | 2024.02.19 |